アリババのQwenチーム、52言語対応音声認識モデル「Qwen3-ASR」をオープンソース化
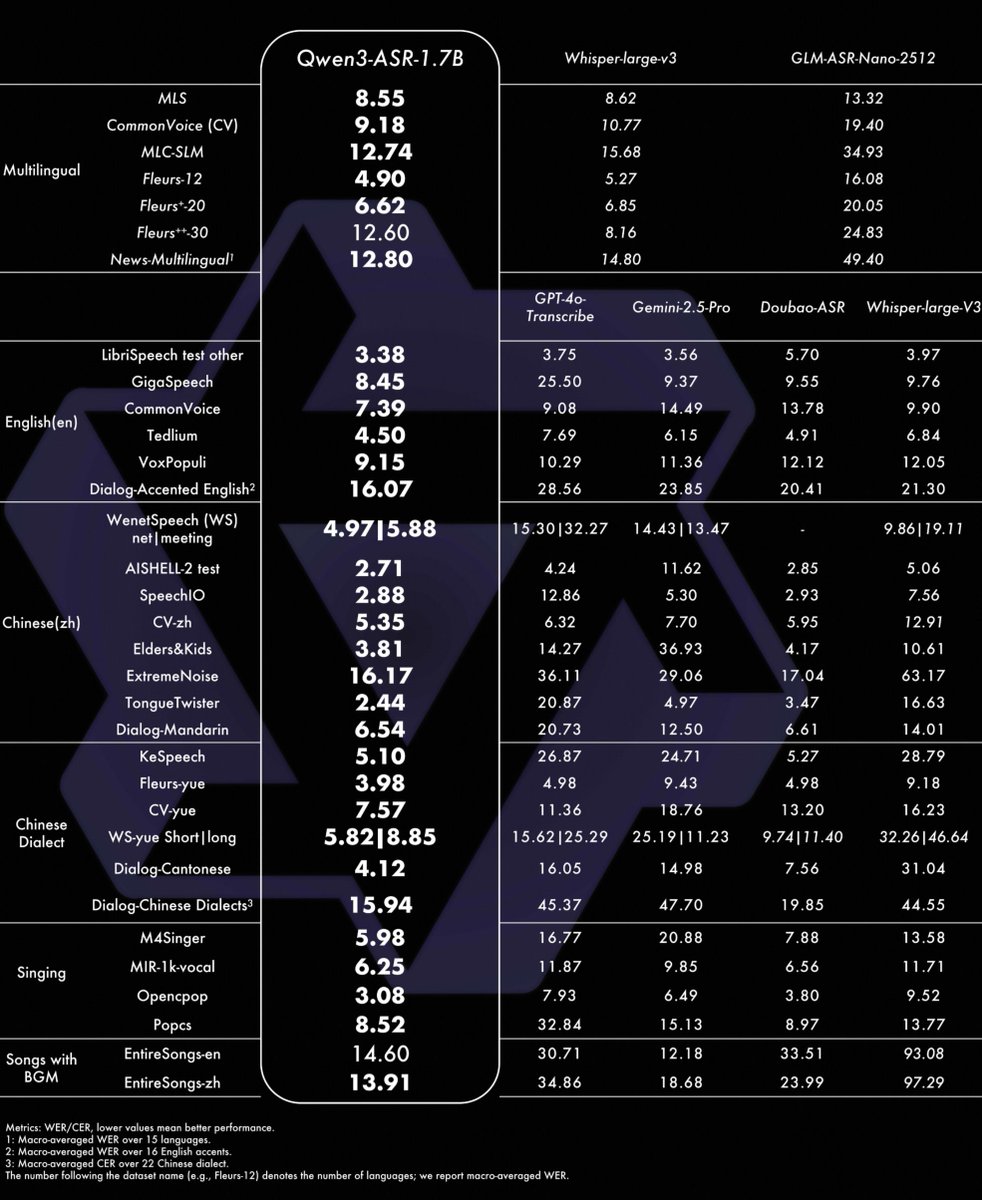
アリババのQwenチームは、ノイズの多い実世界オーディオで優れた性能を発揮する生産準備完了の音声認識モデル「Qwen3-ASR」と「Qwen3-ForcedAligner」をオープンソース化した。これらは52言語・方言をサポートし、最大20分間のオーディオクリップに対応、11言語で高精度な単語レベル時刻スタンプを提供する。
アリババのQwenチームは、実世界の雑多なオーディオ環境に最適化された生産準備完了の音声モデル「Qwen3-ASR」と「Qwen3-ForcedAligner」の2つをオープンソース化した。これらは競争力のある性能と高い頑健性を備えている。
Qwen3-ASRは52言語・方言をサポートし、30言語の自動言語識別と22の方言・アクセントに対応する。ノイズの多い複雑な環境や歌唱などのシナリオで頑健性を示し、1回の処理で最大20分間の長いオーディオセグメントを扱う。
ASR機能を補完するQwen3-ForcedAlignerは、11言語で単語・フレーズレベルの高精度アライメント時刻スタンプを提供する。従来のMFA、CTC、CIFスタイルのアライナーを上回る性能を示している。
リリースにはvLLMと統合された完全なオープンソース推論・ファインチューニングスタックが含まれており、バッチ処理、ストリーミング、非同期サービングをサポートする。注目モデルとしてQwen3-ASR-0.6BとQwen3-ForcedAligner-0.6Bが挙げられ、アーキテクチャ詳細とリアルタイムファクター(RTF)ベンチマークが公開されている。
開発者はGitHub(github.com/QwenLM/Qwen3-ASR)、Hugging Faceコレクション(huggingface.co/collections/Qwen)、ModelScope(https://modelscope.cn/collections/Qwen/Qwen3-ASR)からモデルにアクセス可能だ。インタラクティブデモはHugging Face Spaces(huggingface.co/spaces/Qwen)とModelScope Studios(modelscope.cn/studios/Qwen/Qwen3-ASR)で利用できる。
プロジェクトブログ(qwen.ai/blog)と技術論文(https://github.com/QwenLM/Qwen3-ASR/blob/main/assets/Qwen3_ASR.pdf)も参照可能である。今回のリリースにより、多言語アプリケーション向けの高性能音声処理ツールのアクセシビリティが向上した。
重要ポイント
- 52言語および方言(30言語+22方言・アクセント)
- 1パスあたり最大20分間の音声
- 11言語の高精度アライメント
- 歌唱を含む騒音・複雑な環境下でも堅牢
- Qwen3-ASR-0.6BおよびQwen3-ForcedAligner-0.6Bモデル
- バッチ・ストリーミング・非同期サービング向けのvLLM統合