アリババのQwen、適応型ツール活用の最先端推論モデル「Qwen3-Max-Thinking」を公開
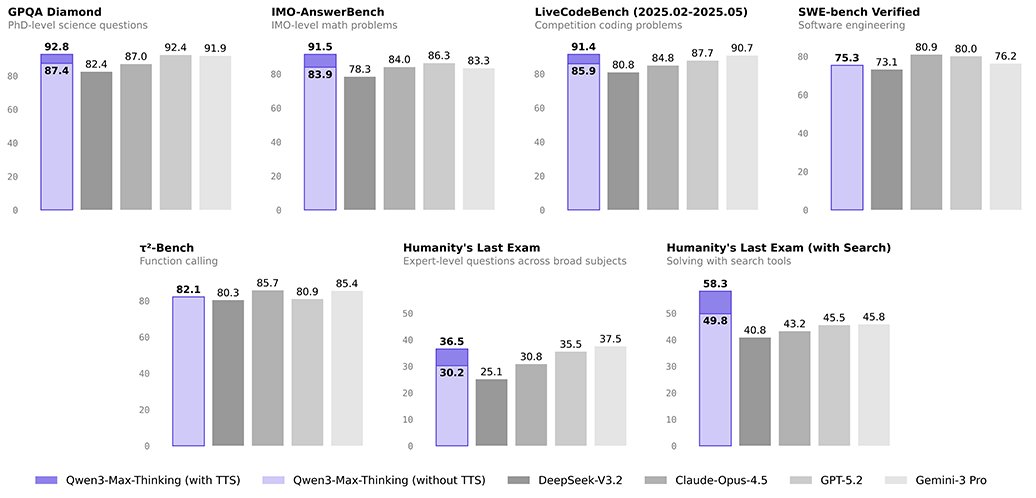
アリババのQwenチームが、大規模計算資源と強化学習(RL)で訓練した最先端推論モデル「Qwen3-Max-Thinking」を公開した。HMMT数学競技で98.0を達成し、Gemini 3 Proを上回る自己反省機能を備える。
アリババのQwenチームは、最も高性能な推論モデル「Qwen3-Max-Thinking」を公開した。このモデルは、大規模な計算資源と先進的な強化学習(RL)を用いて訓練されており、推論、知識検索、ツール活用、エージェント機能で優れた性能を発揮している。
主な革新点として、適応型ツール活用が挙げられる。モデルはSearch、Memory、Code Interpreterなどのツールを、手動介入なしで智能的に選択・活用する。また、テスト時スケーリングにより、多段自己反省を組み込み、Gemini 3 Proを上回るベンチマーク成績を達成した。
モデルは厳しい評価で優位性を示した。HMMT 2月数学競技で98.0、HLEエージェント検索ベンチマークで49.8を記録した。各種ドメインの詳細スコアをまとめた評価表が、その広範な能力を裏付けている。
Qwen3-Max-Thinkingは、アリババ・クラウドのQwenシリーズ大規模言語モデルを基盤とする。開発者はOpenAI形式対応のCompletions APIおよびResponses API経由で利用可能で、コードサンプル、料金、ドキュメントが提供されている。
ユーザーはQwenチャットプラットフォームで適応型推論を直接体験できる。公式ブログでは訓練手法、評価結果、展開オプションの詳細が解説されている。
この公開により、Qwen3-Max-Thinkingは次世代AI推論のトップランナーとして位置づけられ、多様なアプリケーションでの深い思考と難問解決を可能にする。
重要ポイント
- 大規模スケールと先進的なRLで訓練された
- 適応型ツール使用:サーチ、メモリ、コード・インタープリタ
- マルチラウンド自己反省を伴うテスト時スケーリングがGemini 3 Proを上回る
- HMMT Feb数学ベンチマークで98.0
- HLEエージェント的サーチベンチマークで49.8