Baseten、Speculation Engineの受理率を最大40%向上
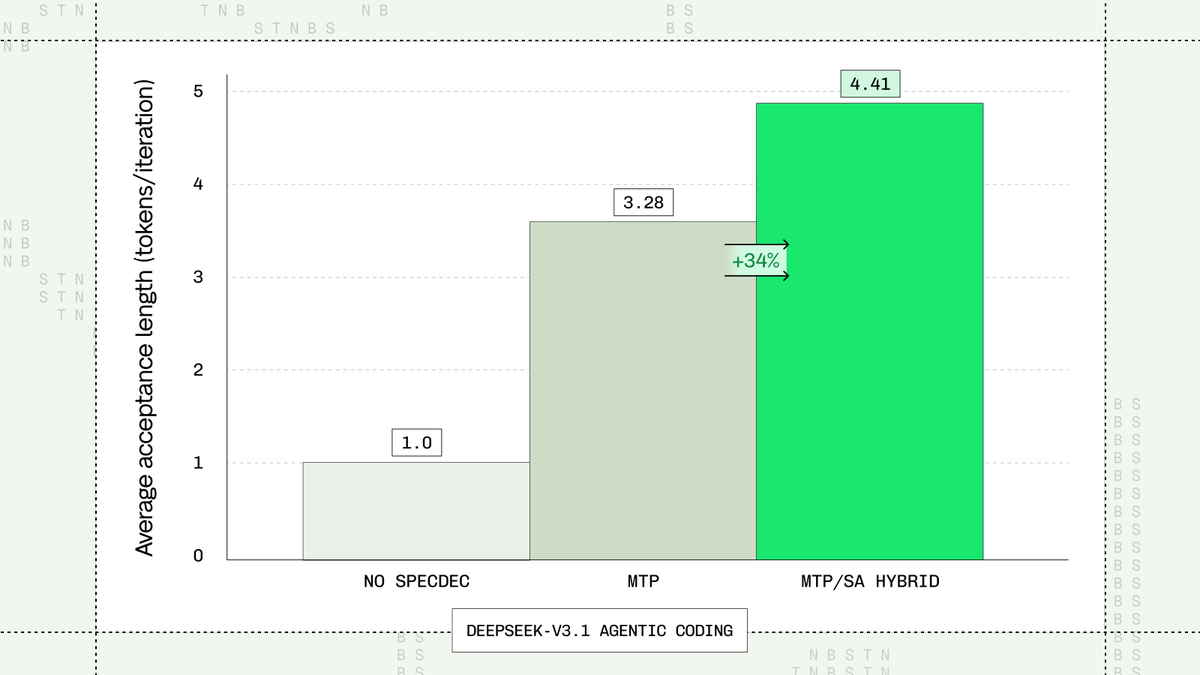
BasetenはMulti-Token PredictionとSuffix Automatonデコーディングを組み合わせたSpeculation Engineの強化を実施。コード編集タスクで受理率を最大40%向上させ、受理長を30%以上延長した。追加計算オーバーヘッドなしでTensorRT-LLM向けオープンソース版を公開した。
BasetenはSpeculation Engineの大幅なアップグレードを発表した。この強化ではMulti-Token Prediction(MTP)とSuffix Automaton(SA)デコーディングを組み合わせることで、受理率を最大40%向上させた。
本技術は本番環境のコーディング作業を対象としており、コード編集タスクで受理長を30%以上延長する成果を上げた。追加の計算オーバーヘッドは一切発生しない。
Speculation EngineはBasetenのプラットフォームの主要コンポーネントであり、大規模言語モデルの推論速度を向上させるための投機的デコーディングを担う。MTPによる複数トークン同時予測とSAデコーディングによるサフィックスマッチング最適化により、従来手法を上回る受理率を実現した。
社内評価の主な指標では、受理率が最大40%増加し、コード生成・編集時のレイテンシを低減する長い投機シーケンスを可能にした。これはAI支援コーディングツールに依存する開発者や企業にとって価値が高い。
コミュニティの採用を促進するため、BasetenはNVIDIAの高性能推論ライブラリTensorRT-LLM向けの実装をオープンソース化した。開発者はこれをワークフローに自由に統合できる。
詳細はBasetenのエンジニアリング深掘りブログ(baseten.co/blog/boosting-mtp-acceptan...)で確認可能だ。
本リリースはBasetenの効率的なAI推論推進への取り組みを強調するものである。
重要ポイント
- 受理率が最大40%向上
- コード編集タスクにおける受理長が30%以上長い
- 追加オーバーヘッドがゼロ
- TensorRT-LLM向けオープンソース版が利用可能